For years I have been led to believe that using the bulk-logged recovery model for SQL Server databases was a safe place to be in (that was entirely my fault, not MSDN’s nor TechNet’s.) I took it upon myself the definition of this recovery model – MINIMAL log space is used by bulk operations. My understanding from this definition was that it will only use minimal space in the transaction log while performing transactions in this recovery model. Wasn’t that the definition in the first place? I was wrong – for many years. You see, being in the bulk-logged recovery model may mean using minimal log space for transactions but that’s for a reason. Being in this recovery model means that the log will not contain all of the changes made by a transaction – only enough changes to recreate the end result. An analogy for this scenario would be like hopping on one of those computerized treadmills. If I wanted to spend half an hour on the treadmill, all I need to do is set it to half an hour. In my mind, I will do a half-hour of treadmill work. During the course of me going thru my exercise routine, I may bump up the speed to 2 mph for the first 5 minutes to warm myself up, maybe up to 5 mph for next 5 minutes, up to 7 mph for the next 10 minutes, start to cool down on the next 5 minutes at 3 mph and possibly do deep breathing exercises for the last 5 minutes at 2 mph. At the end of my exercise routine, I would have done half an hour of treadmill work, which was what I set out to accomplish initially. But what if I want to recreate the exact same routine with the combination of speed and duration on the treadmill? The only way for me to do that is to look at the record in the treadmill and note when I changed the speed, at what time and for how long. The treadmill keeps all that information, therefore, I can say that it is in the FULL recovery model. Since I have very limited memory, I am in the BULK_LOGGED recovery model. I don’t have to keep all of that information in my brain, just enough to recreate what I just did.
Going back to the discussion about recovery models, switching to bulk-logged recovery model during some high volume transactions may be a good idea to minimize the amount of log space used. But have we thought about the risks that we are getting our databases into when we switch to this recovery model? Since it does not have enough information in the log to recreate a transaction running while in this recovery model, we run the risk of not being able to do a point-in-time recovery of the database. Here’s an example. Let’s say we switch our database to the bulk-logged recovery model prior to running an index maintenance job to minimize its impact on our log shipping configuration. If something happens to the database before the next transaction log backup, we end up running a tail-of-the-log backup that is potentially corrupt. Since the bulk-logged recovery model does not have all of the changes made in the transaction log, a log backup will need to grab the changes in the affected data files in order to keep the database consistent during a restore process. If the log backup only took the transaction log records, restoring that particular backup would render the database inconsistent. However, in the Full recovery model, all of the changes are already in the transaction log. A log backup no longer needs to access the data files to record those changes. This is one of the reasons why we can still recover the database to a specific point-in-time prior to a disaster by using a tail-of-the-log backup. To illustrate, let’s say I will create a database with a simple table and a clustered index.
GO
CREATE TABLE testTable (
c1 INT IDENTITY,
c2 VARCHAR (100));
GO
CREATE CLUSTERED INDEX testTable_CL
ON testTable (c1);
GO
Next, I’ll insert several rows in the table and take my very first full database backup. My backup will then contain the record that I just inserted.
INSERT INTO testTable
VALUES ('Row inserted: transaction # 1');
GO
BACKUP DATABASE [testDB] TO
DISK = 'C:DemostestDB.bak'
WITH INIT,STATS, STATS;
GO
I will, then, insert 100 additional rows in the table and take my first log backup. The log backup will contain all of those 100 rows that I just added.
INSERT INTO testTable
VALUES ('Insert more rows...');
GO 100
BACKUP LOG testDB TO
DISK = 'C:DemostestDB_Log1.trn'
WITH INIT,STATS, STATS;
GO
Assume that I will switch the database recovery model to bulk-logged because I will be doing an index maintenance.
ALTER DATABASE testDB
SET RECOVERY BULK_LOGGED;
GO
ALTER INDEX testTable_CL ON testTable REBUILD;
GO
I’ll switch the database back to the FULL recovery model after the index maintenance and add more rows.
ALTER DATABASE testDB
SET RECOVERY FULL;
GO
INSERT INTO testTable
VALUES ('Row inserted: transaction # 2');
GO
INSERT INTO testTable
VALUES ('Row inserted: transaction # 3');
GO
Now, since we haven’t done any backups yet after switching to bulk-logged recovery model and back to FULL, the next log backup will have to look at the data files and grabs the changed data pages (and index pages, in this case) to keep the database consistent. If this was in the FULL recovery model, all that the backup process needs is the transaction log file. What if the server crashes and corrupted the data files containing the table? The first thing that we need to do to restore the database to a point-in-time prior to the crash is to do a tail-of-the-log backup and use that as the last step in our restore process. Let’s try that.
-- Backup the tail-of-the-log so we can keep the transactions that are still in the log but not persisted to the data files
BACKUP LOG [testDB] TO
DISK = 'C:DemostestDB_tail.trn'
WITH INIT,STATS, NO_TRUNCATE;
GO
Notice that while the tail-of-the-log backup may have succeeded, it generates a message that is a bit alarming. Wouldn’t you consider this as something to be worried about?
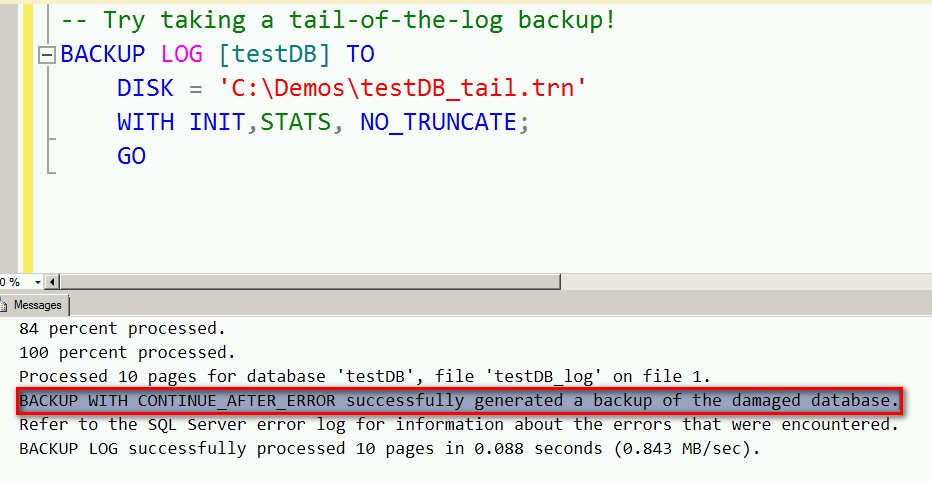
Basically, the tail-of-the-log backup encountered an error in the process but continued anyway. That also means that we can’t really rely that much on this backup. Let’s try restoring this tail-of-the-log backup as part of our restore sequence.
-- Try restoring from backups
RESTORE DATABASE [testDB] FROM
DISK = 'C:DemostestDB.bak'
WITH REPLACE, NORECOVERY;
GO
RESTORE LOG [testDB] FROM
DISK = 'C:DemostestDB_Log1.trn'
WITH REPLACE, NORECOVERY;
GO
--Restore the tail-of-the-log backup
RESTORE LOG [testDB] FROM
DISK = 'C:DemostestDB_tail.trn'
WITH REPLACE;
GO
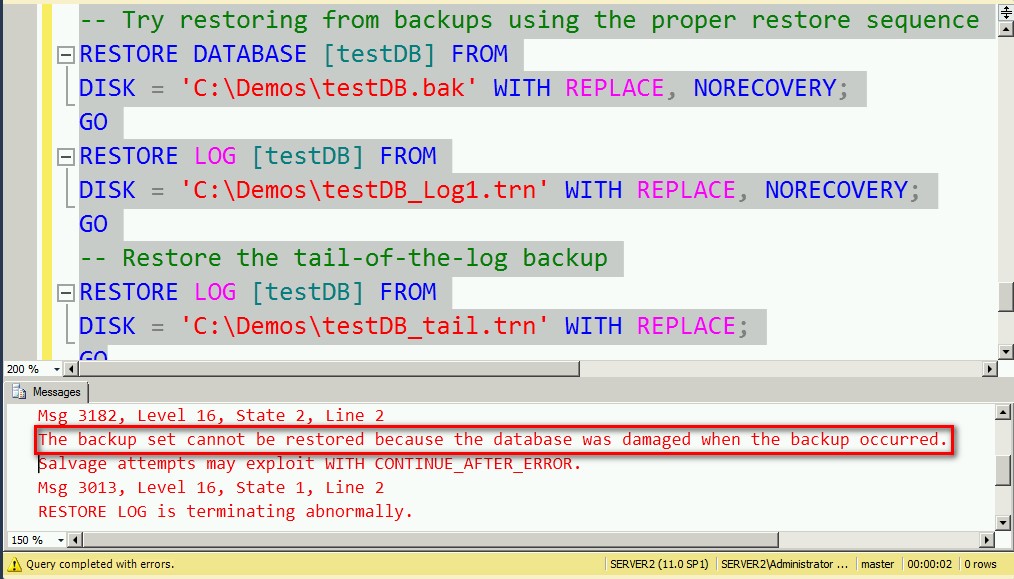
Because the database was switched to bulk-logged recovery model and there was no other backup that occurred prior to the disaster, the tail-of-the-log backup that we were trying to attempt did not contain enough information to recreate the index maintenance task that we did. In order to properly recreate that transaction, the backup process needed to access the data files that have been changed by the transaction. Since the data file in this case was damaged, there was no way for the tail-of-the-log backup to capture that information, thus, rendering it as corrupt.
This should give you some insights into the risk that your databases are in by switching to the bulk-logged recovery model. So, what do you need to do to avoid this risk? Make sure that you run a backup immediately after the transactions you are running under the bulk-logged recovery model complete. That backup will certainly include all of the data pages that were changed by the minimally logged transaction and would be enough to recover your database should something happen afterwards. A graphic of how that can be done is highlighted in the MSDN article.

Backup sequence when switching from FULL to BULK_LOGGED recovery model and back.
Don’t say I didn’t warn you.
Hi Edwin
Running your script on SQL Server 2012 11.0.2100, I cannot get the error message from the last restore , but it completes successful
Hi Yuri,
Did you switch to BULK_LOGGED recovery model prior to running an index rebuild? The best way to check is to look at the DifferentialBaseLSN column of the backups you took. Here’s a reference blog post about looking at the DifferentialBaseLSN column of your backup files
http://blogs.msdn.com/b/suhde/archive/2009/03/14/working-with-multibase-differential-backups.aspx